Los registros médicos electrónicos son utilizados para mejorar la atención de los pacientes, medir el rendimiento de prácticas clínicas o facilitar la investigación clínica.
Los modelos de aprendizaje automático pueden ser entrenados a través de datos de registros de salud electrónicos (EHR, en inglés). De esta forma se pueden realizar predicciones sobre la probabilidad de desarrollar enfermedades como la diabetes, realizar seguimientos de los pacientes o predecir cómo responderán a medicamentos específicos.
Sin embargo, para llevar a cabo esta tarea es necesario tener acceso a datos de EHR, lo que es un gran desafío ya que están protegidos por regulaciones de confidencialidad que garantizan su privacidad. Para tomar datos de EHR y realizar estudios, es necesario que los investigadores obtengan el consentimiento de los pacientes.
No obstante, existen métodos para anonimizar datos, por ejemplo, la desidentificación, pero son costosos y pueden eliminar o distorsionar características importantes de los conjuntos de datos originales, disminuyendo su utilidad.
En este sentido, científicos de Google Research desarrollaron EHR-Safe: Generación de registros de salud electrónicos sintéticos de alta fidelidad y preservación de la privacidad un modelo para la generación de datos sintéticos con las propiedades que su nombre menciona: alta fidelidad, es decir que son útiles para una tarea de interés especifico y cuentan con medidas privacidad, es decir que no revelan información real de los pacientes.

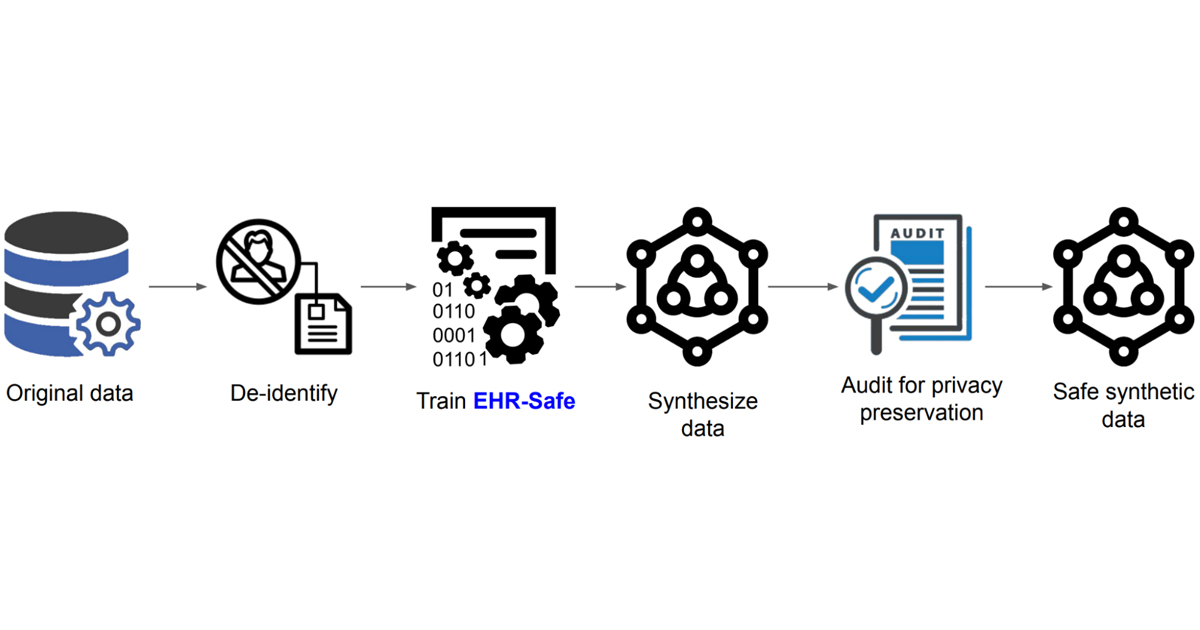
Los científicos de Google Research se enfrentaron con múltiples desafíos para la generación de EHR sintéticos, específicamente relacionados con las características de los EHR reales. Las características pueden ser numéricas o categóricas algunas variables son estáticas otras cambian con el tiempo, por ejemplo, a través de exámenes de laboratorio regulares o esporádicas. Es decir, algunos pacientes dependiendo de su condición de salud, realizan visitas clínicas de manera regular y sus datos cambian constantemente.
El modelo EHR-Safe está construida en una arquitectura de codificador-descodificador secuencial y redes antagónicas (GAN en inglés). Es decir, el modelo aprende el mapeo de los datos brutos de los EHR.
“Las métricas de fidelidad se centran en la calidad de los datos generados sintéticamente al medir la realidad de los datos sintéticos. Una mayor fidelidad implica que es más difícil diferenciar entre datos sintéticos y reales. Evaluamos la fidelidad de los datos sintéticos en términos de múltiples análisis cuantitativos y cualitativos”, explican los autores.
Consulta el artículo con los detalles completos en el siguiente enlace: