Un estudio reciente evaluó el desempeño del modelo de aprendizaje profundo Mirai frente al criterio de densidad mamaria en la predicción del cáncer de mama a cinco años, con resultados que cuestionan las políticas de tamizaje vigentes en Estados Unidos.
Un equipo de investigadores del Massachusetts General Hospital y la Harvard Medical School analizó 123,091 mamografías de detección realizadas entre 2009 y 2018 en 67,019 pacientes, con seguimiento hasta 2023, para comparar la capacidad predictiva del modelo de deep learning or deep learning, Mirai con la clasificación de densidad mamaria establecida por el sistema BI-RADS del Colegio Americano de Radiología. Los resultados publicados en JAMA Network Open, muestran que el modelo de artificial intelligence (AI) ofreció una discriminación significativamente mayor para estimar el riesgo de cáncer a cinco años, con un área bajo la curva ROC de 0.71, frente a 0.53 del criterio de densidad.
El contexto regulatorio del estudio tiene relevancia directa: desde septiembre de 2024, la Administración de Alimentos y Medicamentos (FDA, en inglés) exige que los centros de imagenología notifiquen a las pacientes si sus mamas son densas o no densas, y más de 30 estados cuentan con legislación que amplía la cobertura de seguro para estudios complementarios en mujeres con mamas densas. Sin embargo, los autores señalan que esta clasificación binaria, es decir densa contra no densa, aplica al 40 o 50% de las mujeres sometidas a tamizaje, se determina mediante evaluación visual subjetiva con variabilidad conocida entre radiólogos, y no refleja necesariamente el riesgo individual de cada paciente.
El modelo Mirai, desarrollado conjuntamente por el MIT y el Massachusetts General Hospital, genera una puntuación de riesgo absoluto a uno y cinco años a partir de las cuatro proyecciones estándar de la mamografía convencional en dos dimensiones, sin requerir cuestionarios clínicos ni datos adicionales de la paciente. En el estudio, las pacientes clasificadas como de alto riesgo por el modelo, como aquellas con una puntuación superior al 3%, presentaron una incidencia de cáncer del 6.2%, frente al 1.0% en el grupo de bajo riesgo. Además, mujeres con mamas no densas pero clasificadas como de alto riesgo por el modelo registraron una incidencia del 6.0%, comparable al 6.4% observado en mujeres con mamas densas y alto riesgo por AI, lo que evidencia que la densidad por sí sola resulta insuficiente para estratificar el riesgo de manera precisa.
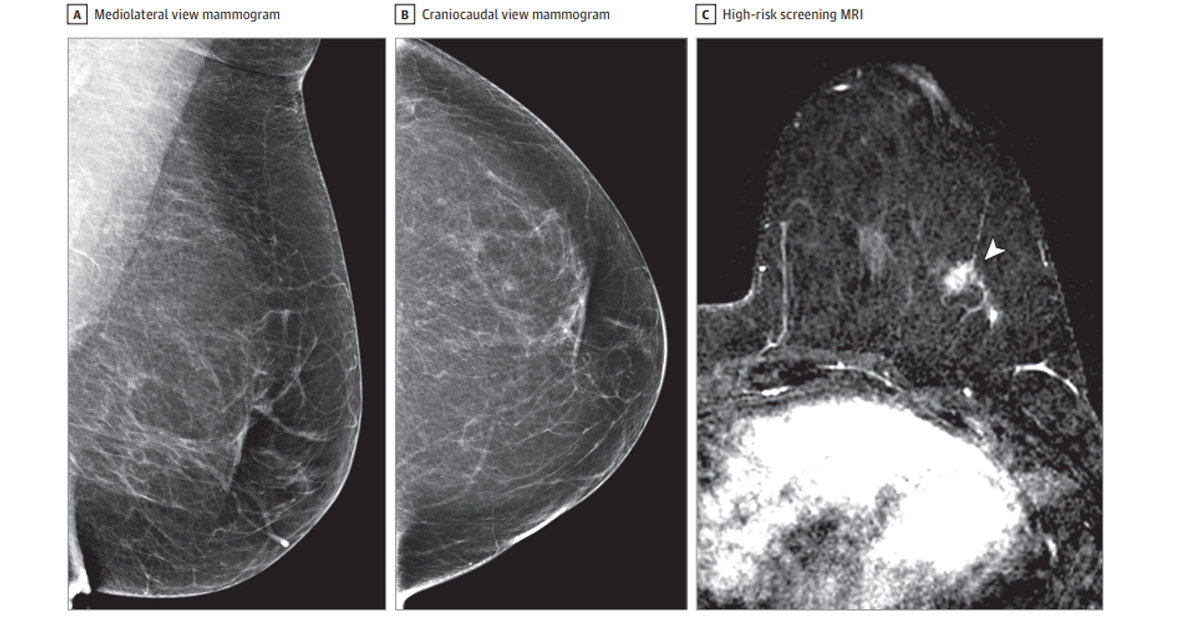
En cuanto a los resultados falsos negativos, definidos como mamografías interpretadas como normales o benignas seguidas de un diagnóstico de cáncer dentro del año siguiente, las tasas también aumentaron de manera escalonada conforme subía el puntaje de riesgo del modelo: 0.6 por cada mil estudios en el grupo de bajo riesgo, 1.0 en el intermedio y 2.1 en el de alto riesgo. La mayor tasa de falsos negativos se registró en mujeres con mamas densas y puntuación alta de AI, 3.0 por cada mil estudios, mientras que la menor correspondió a mujeres con mamas no densas y bajo riesgo según el modelo, es decir 0.2 por cada mil estudios. Añadir la densidad mamaria al modelo de AI no mejoró su desempeño discriminatorio.
El rendimiento del modelo fue consistente en los análisis por subgrupos raciales y étnicos. Entre pacientes blancas, el área bajo la curva fue de 0.70 para el modelo de AI frente a 0.53 para la densidad; entre pacientes asiáticas, 0.69 frente a 0.54; entre pacientes negras, 0.72 frente a 0.57, y entre pacientes hispanas, 0.69 frente a 0.56.
Los autores reconocen que se trata de un estudio retrospectivo en un solo sistema hospitalario académico con un único proveedor de equipos de imagenología, lo que puede limitar la generalización de los hallazgos. La cohorte fue predominantemente blanca, el modelo fue desarrollado sobre imágenes de mamografía digital convencional en dos dimensiones sin incorporar tomosíntesis, y los umbrales de riesgo utilizados, que están basados en los criterios del National Comprehensive Cancer Network, requieren validación prospectiva antes de su adopción clínica extendida. El número relativamente pequeño de resultados falsos negativos también restringió la precisión de los estimados en los análisis de subgrupos.