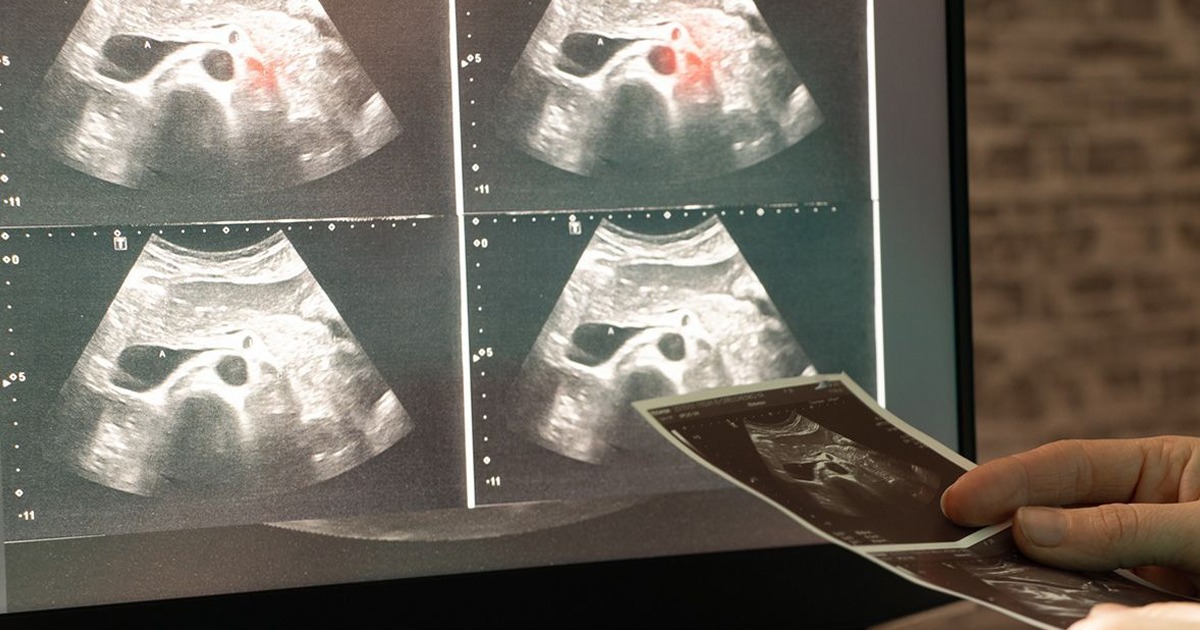
El nuevo modelo, GenSeg, mejora significativamente el análisis de imágenes médicas incluso con cantidades mínimas de datos etiquetados.
Un equipo de investigadores de instituciones como la Universidad de California en San Diego y Stanford desarrolló un marco de deep learning or aprendizaje profundo llamado GenSeg, capaz de generar imágenes médicas y máscaras de segmentación de alta calidad. Este avance, publicado en Nature Communications, permite entrenar modelos precisos de segmentación incluso en contextos con escasez extrema de datos, lo que podría transformar el diagnóstico y tratamiento médico en entornos clínicos con recursos limitados.
La segmentación semántica de imágenes médicas es esencial para diagnosticar enfermedades, planificar tratamientos y asistir intervenciones quirúrgicas. Sin embargo, entrenar modelos de aprendizaje profundo confiables requiere grandes volúmenes de imágenes etiquetadas por expertos, lo cual resulta costoso y complicado. Esta limitación ha llevado al desarrollo de GenSeg, una solución innovadora basada en inteligencia artificial generativa.
“Este proyecto nació de la necesidad de romper este cuello de botella y hacer más prácticas y accesibles potentes herramientas de segmentación, especialmente para escenarios en los que los datos son escasos”, expresó Li Zhang, primer autor del estudio y estudiante de doctorado en UC San Diego.
GenSeg emplea un proceso de optimización multinivel (MLO, en inglés) que guía la generación de datos sintéticos en función del rendimiento de los modelos de segmentación. A diferencia de métodos tradicionales de aumento de datos o enfoques semi-supervisados, GenSeg genera pares imagen-máscara directamente vinculados al objetivo de mejorar la segmentación.
Los resultados fueron validados en 19 conjuntos de datos médicos, abarcando diversas enfermedades, órganos y modalidades de imagen, como ecografías, radiografías, tomografías ópticas y cámaras estándar. En todos los casos, GenSeg logró mejoras absolutas de 10 a 20% en precisión, incluso utilizando hasta 20 veces menos datos que otros métodos.
Además, GenSeg demostró un rendimiento sólido en escenarios fuera del dominio original de entrenamiento o out-of-domain, lo cual es crucial para su aplicación en el mundo real. Por ejemplo, usando solo 9 o 40 imágenes anotadas, el modelo fue capaz de generalizar correctamente en conjuntos de datos completamente nuevos.
Frente a herramientas de aumento de datos ampliamente usadas, como la rotación o la inversión de imágenes, y modelos generativos tradicionales, GenSeg presentó un desempeño consistentemente superior. También superó a métodos semi-supervisados, sin necesidad de imágenes no etiquetadas adicionales, lo que refuerza su aplicabilidad práctica.
El marco GenSeg es agnóstico al modelo base, lo que permite integrarlo con arquitecturas populares como UNet, DeepLab o incluso modelos basados en transformadores como SwinUnet. Además, puede extenderse a tareas de segmentación en 3D, ampliando su utilidad en contextos clínicos más complejos.
“En lugar de tratar la generación de datos y la formación del modelo de segmentación como dos tareas separadas, este sistema es el primero en integrarlas. El propio rendimiento de la segmentación guía el proceso de generación de datos. De este modo se garantiza que los datos sintéticos no sólo sean realistas, sino que estén específicamente adaptados para mejorar la capacidad de segmentación del modelo”, indicó Zhang.