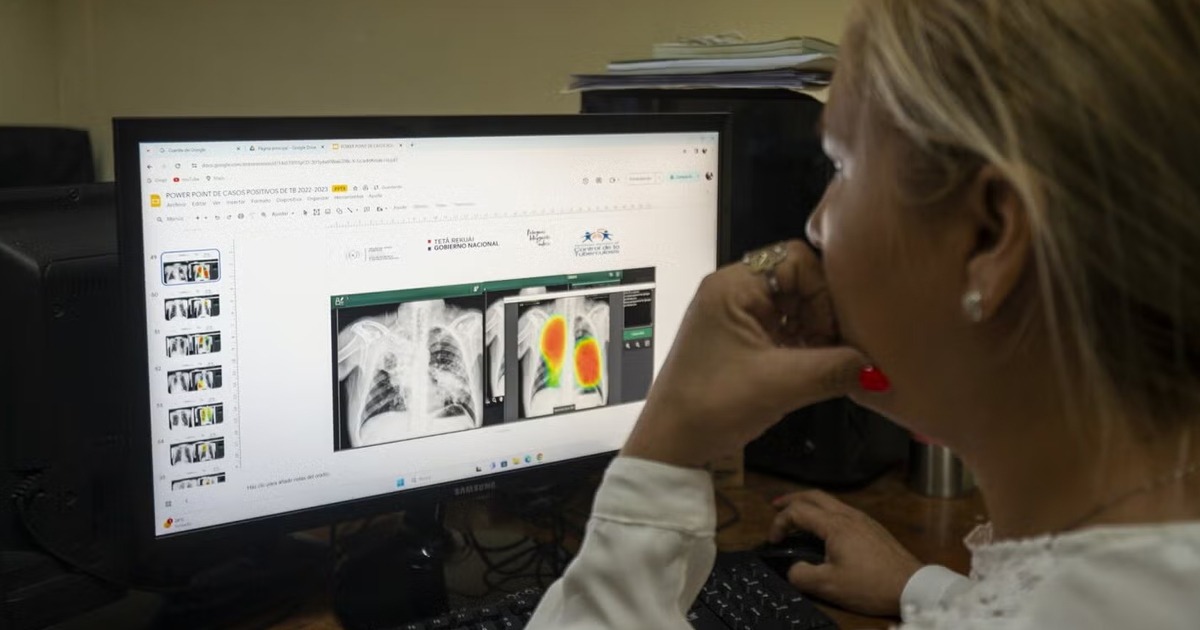
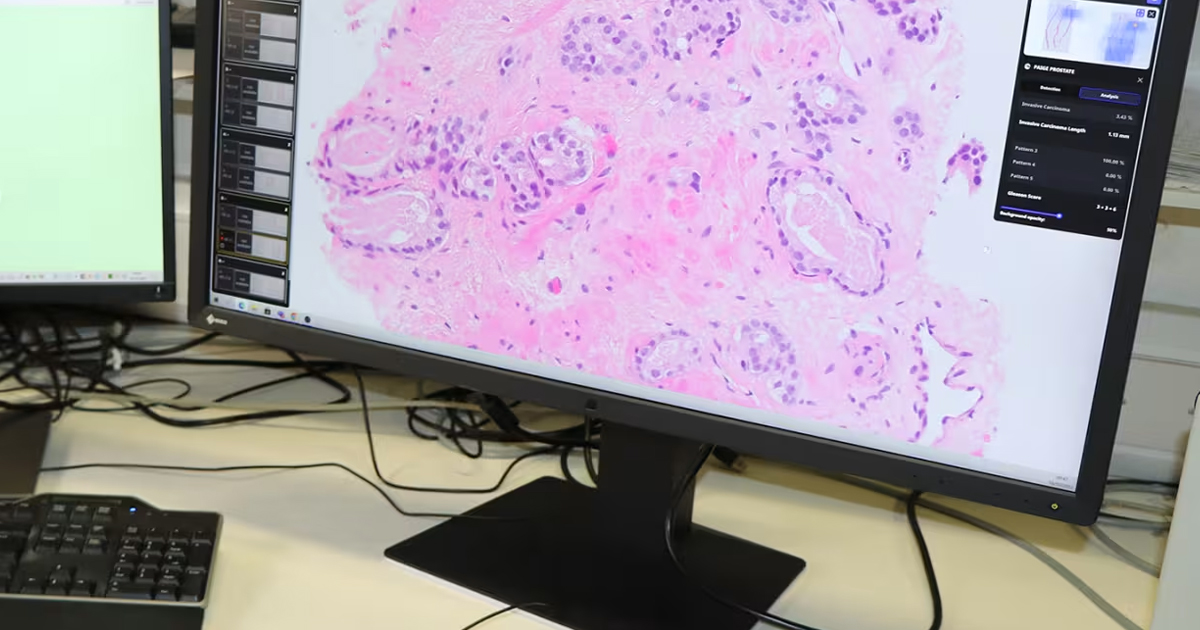
La revolución tecnológica ha permitido que herramientas informáticas y de Inteligencia Artificial (IA) como el aprendizaje automático, sean utilizadas en el sector salud para apoyar las decisiones clínicas y diagnósticos.
El aprendizaje automático se ha convertido en una herramienta muy utilizada en el sector salud para apoyar la toma de decisiones clínicas e incluso mejorar diagnósticos. Esta herramienta se nutre de valores de pruebas de laboratorio, protocolos de imágenes o puntuaciones de exámenes físicos, por ejemplo. Gracias a esto algunos diagnósticos pueden realizarse solo con un valor de laboratorio como en condiciones como la diabetes en adultos mayores.
Por otra parte, otro tipo de diagnósticos se basan en signos, síntomas, valores de laboratorio e imágenes de apoyo, no obstante, estos diagnósticos requieren una mezcla de características positivas y negativas. Los diagnósticos clínicos pueden no considerar la entrada de datos dispares o relaciones no lineales que son limitadas por las capacidades humanas de toma de decisiones. El soporte algorítmico para la toma de decisiones puede utilizarse para facilitar dichas tareas en búsqueda de resultados más exitosos.
En este sentido, la medicina de precisión es de suma importancia, pues su objetivo es crear un modelo médico que personalice la atención médica que se adapten al fenotipo de un individuo o paciente. Es decir, aspectos como el seguimiento longitudinal de trayectorias de salud, genética y epigenética, modelos matemáticos, entre otros.

“Es a través del modelado computacional y la fusión de información que los resultados de interés, como los objetivos de tratamiento y medicamentos, en última instancia, facilitan una mejor toma de decisiones a nivel del paciente en esos centros de atención”, explican autores de una revisión de alcance sobre la salud de precisión publicado en npj Digital Medicine.
Los autores del estudio explican que la información se mueve en un patrón cíclico desde los centros de salud hasta los bienes comunes de información, donde se puede transformar y realizar el modelado algorítmico. Es decir, datos demográficos de laboratorio, imágenes médicas, notas clínicas entre otra información puede transformarse en información nueva, modelados y algoritmos, cuyo resultado se puede traducir en ensayos clínicos, decisiones de tratamiento, diagnóstico, descubrimiento de medicamentos, fenotipado, entre otras aplicaciones.
Además de la medicina de precisión y el aprendizaje automático, los autores recuperan otro concepto: la fusión de datos, la cual está respaldada por la teoría de la información. La fusión de datos se refiere al mecanismo mediante el cual se fusionan fuentes de datos dispares para crear un estado de información basado en la complementariedad de las fuentes.
Por otra parte, como explican los autores: “La expectativa en el aprendizaje automático es que los esfuerzos de fusión de datos darán como resultado una mejora en el poder predictivo y, por lo tanto, proporcionarán resultados más confiables en configuraciones de validez potencialmente bajas”.
Existen tres tipos principales de fusión de datos a través de aprendizaje automático: temprano (nivel de datos), intermedio (conjunto) y tardío (nivel de decisión):
- La primera se refiere a múltiples fuentes que se convierten al mismo espacio de información.
- La fusión de datos intermedia combina características que combinan a las características distintivas de cada tipo de datos para producir una nueva representación de datos.
- Finalmente, la fusión tardía requiere el entrenamiento de cada modelo y cada uno corresponde a una fuente de datos entrante. Estos toman como fuentes las representaciones simbólicas y las combinan para obtener una decisión más precisa.
Conoce más en el siguiente artículo: https://www.nature.com/articles/s41746-022-00712-8