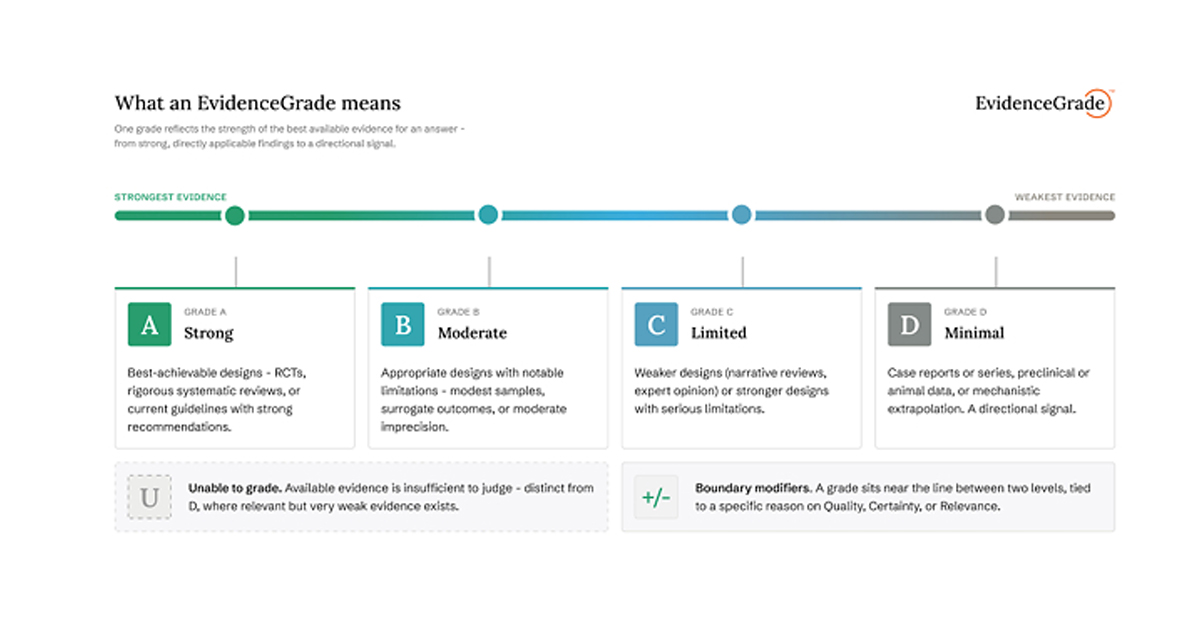
Un estudio reciente evaluó cuatro plataformas de IA como herramientas de enseñanza en farmacia clínica y menos de la mitad de las sesiones cumplió criterios de precisión en todos los dominios evaluados.
La enseñanza en farmacia clínica recurre desde hace décadas a simulaciones de casos para que los estudiantes practiquen el razonamiento terapéutico antes de enfrentarse a situaciones reales. Diseñar esas simulaciones requiere tiempo y experiencia especializada, lo que limita su escala. Los grandes modelos de lenguaje (LLM, en inglés) han surgido como una alternativa para generar ese tipo de contenido de forma automatizada, pero su precisión clínica en áreas terapéuticas complejas no había sido evaluada con rigor. Un estudio publicado en npj Digital Medicine por investigadores de la Universidad de El Cairo aborda esa pregunta y concluye que, aunque los modelos son capaces de estructurar simulaciones pedagógicamente coherentes, su exactitud farmacológica es insuficiente para un uso educativo sin supervisión experta.
El estudio incluyó a 104 estudiantes de doctorado en farmacia que interactuaron con simulaciones clínicas sobre leucemia mieloide aguda (LMA) o leucemia mieloide crónica (LMC), dos enfermedades que comparten características clínicas y terminológicas pero que requieren tratamientos fundamentalmente distintos. Esa proximidad semántica fue elegida precisamente para exponer la tendencia a mezclar información de condiciones relacionadas, una vulnerabilidad conocida de los LLM. Los autores denominan este fenómeno como “entrelazamiento de dominio”. Las simulaciones fueron generadas por cuatro plataformas, Gemini 2.0 Pro, Claude 3.7 Sonnet, DeepSeek V2 y GPT-4o, a partir de instrucciones estructuradas diseñadas por el equipo investigador. Un panel de expertos evaluó las sesiones en tres dominios: diseño instruccional, precisión clínica y seguridad, y fidelidad del razonamiento clínico.
De las 103 sesiones evaluadas, solo 53, el 51.5%, superaron los criterios en los tres dominios simultáneamente. El dominio más débil fue el de precisión clínica y seguridad, con una tasa de aprobación del 58.3%, muy por debajo del diseño instruccional (82.5%) y la fidelidad del razonamiento (81.6%). Esto sugiere que los modelos son más capaces de estructurar una experiencia de aprendizaje que de garantizar la corrección de las recomendaciones terapéuticas que incluyen en ella.
Las sesiones sobre LMC tuvieron mejor desempeño que las de LMA, con tasas de aprobación global de 62.3% frente a 40%, una diferencia estadísticamente significativa. Los errores más graves se concentraron en las sesiones de LMA e incluyeron la recomendación de fármacos propios de otro tipo de leucemia, la atribución incorrecta de síndromes clínicos a tratamientos que no los causan, la desalineación con guías terapéuticas vigentes y, en nueve sesiones, la cita de ensayos clínicos inexistentes con datos estadísticos inventados. Los autores señalan que este último patrón, conocido como alucinación, resulta particularmente problemático en contextos educativos porque el contenido fabricado aparece redactado con el mismo tono de autoridad que el contenido verídico.
El comportamiento varió entre plataformas. Gemini obtuvo la tasa de aprobación global más alta, con 62.1%, seguido de Claude con 59.1%, DeepSeek con 52.2% y GPT-4o con 34.5%, aunque las diferencias entre plataformas no alcanzaron significancia estadística dado el tamaño de la muestra. DeepSeek mostró la variación más marcada según el tipo de enfermedad: aprobó el 84.6% de las sesiones de LMC pero solo el 10% de las de LMA.
Uno de los hallazgos más relevantes del estudio concierne a la percepción de los estudiantes. El 49.8% declaró preferir los modelos de IA sobre los métodos tradicionales, frente al 30% que prefirió los métodos convencionales, y los estudiantes valoraron positivamente la facilidad de uso y el ahorro de tiempo. Sin embargo, el análisis estadístico no encontró correlación significativa entre la satisfacción estudiantil y la calidad clínica de las sesiones evaluada por los expertos. Los estudiantes que interactuaron con sesiones que no superaron los criterios de precisión reportaron niveles de satisfacción similares a los de quienes trabajaron con sesiones aprobadas, lo que indica que la experiencia positiva con el contenido no es un indicador confiable de su corrección farmacológica.
Los autores advierten que esta disociación entre percepción y calidad tiene implicaciones directas para cualquier uso no supervisado de estas herramientas en entornos clínico-educativos. La plausibilidad narrativa de las simulaciones, su fluidez y su tono seguro pueden crear en el estudiante una ilusión de competencia incluso cuando el contenido contiene recomendaciones clínicamente inapropiadas. El estudio concluye que la supervisión experta, con validación específica por plataforma y por enfermedad, sigue siendo indispensable antes de incorporar este tipo de herramientas en la formación clínica.