Un estudio japonés comparó dos modelos de IA con 18 médicos de distintas especialidades y los modelos destacaron en condiciones controladas, pero los especialistas más experimentados mantuvieron ventajas de calibración en validación externa.
Conocer el estado de una mutación genética específica antes de operar es, en el contexto del cáncer cerebral, clínicamente determinante. La mutación del gen IDH o isocitrato deshidrogenasa, divide a los gliomas en quienes la presentan responden mejor a la quimioterapia y a la radioterapia y tienen mayor expectativa de vida, mientras que quienes no la tienen enfrentan una enfermedad más agresiva. Actualmente, confirmar ese estado requiere biopsia o cirugía. Un estudio publicado en npj Digital Medicine por investigadores del Centro Nacional del Cáncer de Japón exploró qué tan cerca están los modelos de inteligencia artificial (IA) de hacer esa determinación de forma no invasiva, solo a partir de imágenes de resonancia magnética, y en qué condiciones superan o no la capacidad de juicio de los médicos.
El estudio comparó dos modelos de aprendizaje profundo o deep learning, GliomaDepth-IDH y GliomaVista-IDH, con 18 médicos de tres perfiles: ocho neurorradiólogos con más de 15 años de experiencia, cinco neurocirujanos especialistas en neuro-oncología y cinco residentes de neurocirugía. Todos evaluaron imágenes los conjuntos de datos BraTS, una base de datos internacional estandarizada usada para el entrenamiento de los modelos, y el JC, una cohorte japonesa multicéntrica con imágenes provenientes de 10 hospitales distintos entre 1991 y 2015, que representa las condiciones variables del entorno clínico real.
Los resultados sobre el conjunto BraTS fueron contundentes en favor de la IA. GliomaVista-IDH, basado en una arquitectura de Vision Transformer, alcanzó un área bajo la curva (AUC) de 0.97, con una precisión del 90%, mientras que los neurorradiólogos obtuvieron un AUC de 0.65, los neurocirujanos de 0.59 y los residentes de 0.54. La ventaja del modelo más avanzado sobre todos los grupos médicos fue estadísticamente significativa.
Sin embargo, al someter los mismos modelos a la validación externa con el conjunto japonés, el rendimiento cayó de forma considerable. GliomaDepth-IDH pasó de un AUC de 0.85 a 0.75, y GliomaVista-IDH de 0.97 a 0.82. Este fenómeno, conocido como “desplazamiento de dominio”, ocurre cuando un modelo entrenado en datos de un entorno se aplica a datos con características distintas, como protocolos de imagen diferentes, volúmenes tumorales más pequeños o variaciones en los equipos de adquisición. Más revelador aún fue el problema de calibración, pues GliomaVista-IDH, con un umbral de clasificación predeterminado, sobrediagnosticó masivamente las mutaciones en la cohorte japonesa, alcanzando una exactitud de apenas 0.64, lo que lo hace inapropiado para uso clínico sin ajustes posteriores.
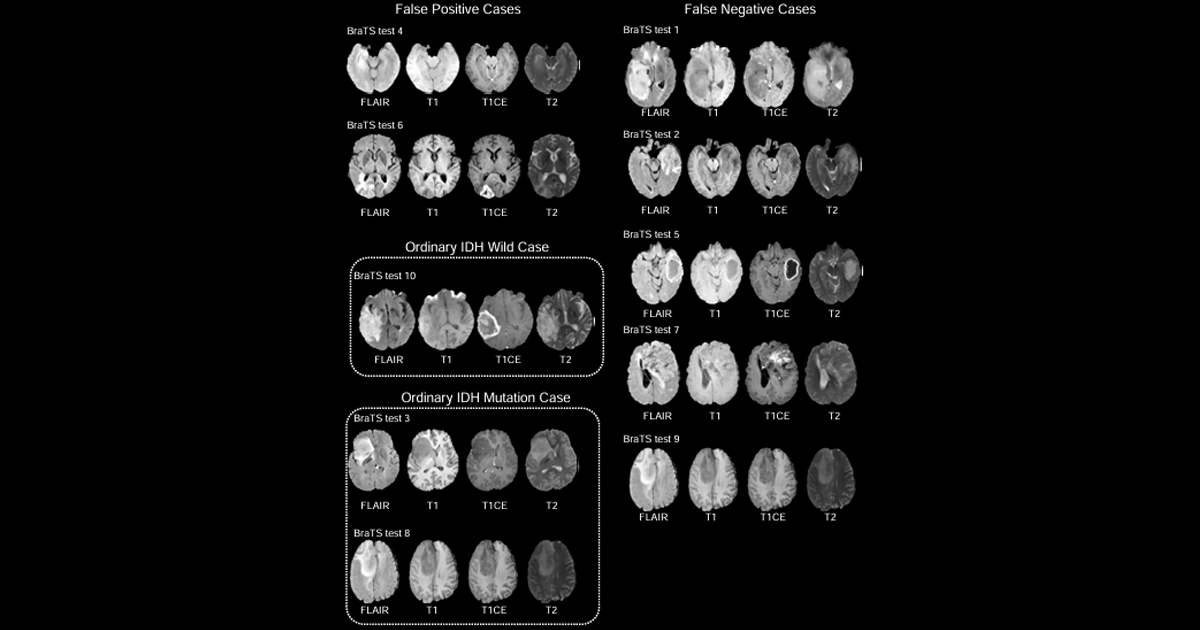
En cambio, un subgrupo de tres médicos de alto desempeño, dos neurorradiólogos y un neurocirujano que obtuvieron AUC superiores a 0.85 en la cohorte japonesa, igualó o superó a los modelos en calibración, con un Brier score de 0.19, mejor que los 0.32 de GliomaVista-IDH en ese mismo conjunto. Los autores señalan que este grupo demostró una capacidad adaptativa ante imágenes de características distintas a las que habitualmente manejan, lo que sugiere que la experiencia clínica profunda confiere estrategias diagnósticas que los modelos actuales no replican plenamente.
Uno de los neurorradiólogos declaró “no tengo idea” ante un caso con una lesión pequeña y características ambiguas, en lugar de emitir una predicción. Los modelos, en cambio, generaron una probabilidad definida para ese mismo caso, sin señal alguna de incertidumbre. Los autores identifican esto como una limitación estructural de los sistemas actuales, ya que la IA produce una estimación numérica independientemente de la calidad o suficiencia de la información disponible, mientras que el médico experimentado puede reconocer cuándo la imagen no permite una conclusión confiable.
Cabe destacar que el estudio incluyó únicamente médicos que ejercen en Japón y se basó en conjuntos de datos relativamente pequeños, con subconjuntos de prueba de diez casos cada uno. Los autores reconocen que estos tamaños limitan el poder estadístico de las comparaciones entre plataformas y especialidades. Los modelos tampoco integraron información clínica, de laboratorio o historial del paciente, recursos con los que los médicos siempre cuentan al emitir un diagnóstico.
Los investigadores concluyen que los modelos de IA tienen un valor claro para asistir a médicos menos experimentados en contextos familiares, pero que su despliegue autónomo requiere adaptación específica al entorno institucional, corrección de calibración y validación local. La propuesta que emerge del estudio apunta hacia sistemas capaces de señalar su propia incertidumbre y hacia marcos de colaboración entre médico y algoritmo que aprovechen las capacidades complementarias de cada uno.