Los datos sintéticos son refieren a información generada artificialmente mediante modelos matemáticos o algoritmos con el propósito de abordar tareas específicas en ciencia de datos.
El uso de datos sintéticos en la atención médica es una tendencia emergente que podría resolver problemas de privacidad y facilitar la investigación, la innovación y el desarrollo de tecnologías sanitarias. Los datos sintéticos son datos generados artificialmente que simulan datos del mundo real pero que no contienen información personal identificable de pacientes, ni información sanitaria protegida. El uso de datos sintéticos contempla diversos aspectos y desafíos como la protección de la privacidad; la innovación y la investigación; el intercambio de datos y la colaboración entre profesionales de la salud; entre otros.
Los datos son fundamentales en la atención médica actual, ya que tienen el potencial de mejorar la atención al paciente, impulsar la investigación clínica y avanzar en iniciativas de salud pública. No obstante, el acceso a conjuntos de datos de alta calidad no está al alcance de todos, lo que frena la investigación y las innovaciones en salud. En este sentido, los datos sintéticos surgen como una alternativa atractiva que aborda cuestiones de privacidad, utilidad de datos, aprobaciones éticas, y sobre todo facilita la investigación al reducir costos.
Uso de datos sintéticos
Los datos sintéticos se han utilizado en otras áreas, como finanzas y economía, sin embargo, su aplicación en la toma de decisiones clínicas enfrenta serios desafíos debido a la responsabilidad y a otros aspectos técnicos, por ejemplo, la replicación precisa de registros médicos originales.
Recientemente en un artículo publicado en npj Digital Medicine, autores exploraron y revisaron técnicas de generación de datos sintéticos, las aplicaciones de estos datos, las definiciones de datos sintéticos en el contexto de la salud, y desafíos de privacidad. Además, propusieron estrategias para mitigar riesgos y aprovechar el verdadero potencial de los datos sintéticos en la investigación médica.
Los autores explican que el término “datos sintéticos” carece de una definición unificada, sin embargo, hace referencia a datos generados artificialmente con el fin de abordar tareas específicas en el campo de ciencia de datos. No obstante, la falta de una definición aceptada universalmente conlleva al uso inconsistente del término. Recientemente, la Royal Society and The Alan Turing Institute definió el término como “datos que han sido generados utilizando un modelo matemático o algoritmo diseñado con el objetivo de resolver una tarea (o conjunto de tareas) de ciencia de datos”.
¿Cómo se generan los datos sintéticos?
En términos de la generación de dato, existen diversas metodologías, desde estructuras de aprendizaje profundo como las Redes Generativas Adversariales (GANs, en inglés) y los Codificadores Variacionales (VAEs, en inglés) hasta modelos econométricos basados en agentes o ecuaciones diferenciales que simulan sistemas físicos o económicos. Estas herramientas automatizadas son capaces de generar conjuntos de datos sintéticos de alta calidad y clínicamente realistas.
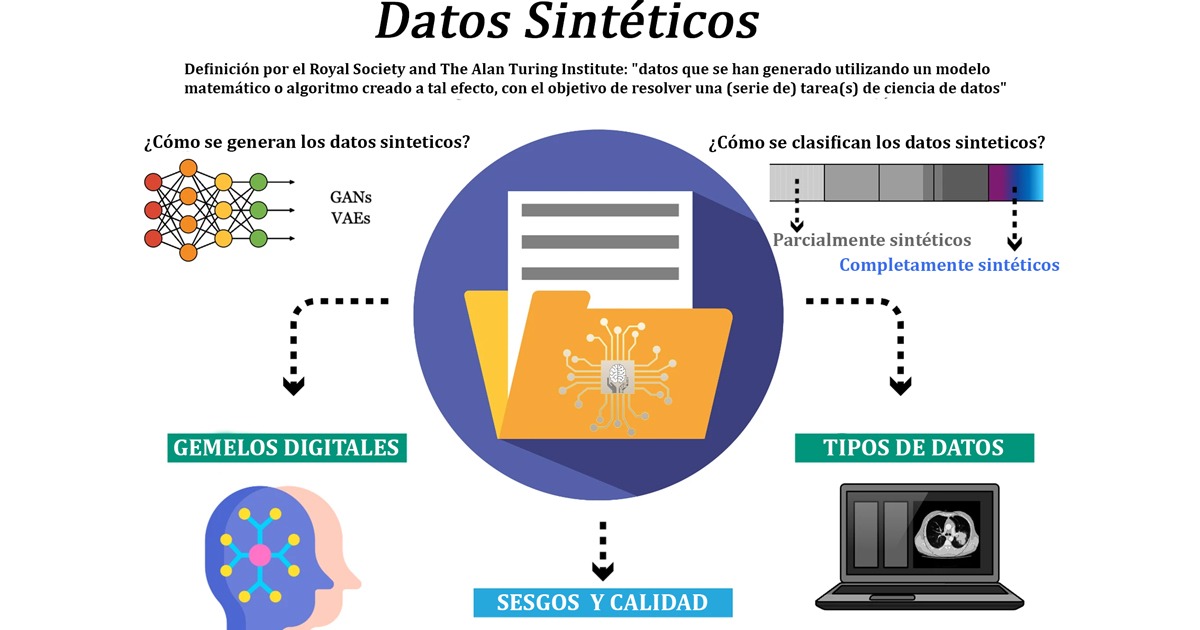
Los datos sintéticos pueden clasificarse como parcialmente sintéticos hasta completamente sintéticos. Los datos parcialmente sintéticos combinan datos del mundo real con datos sintéticos. Este enfoque se ha utilizado en la atención médica para proteger la privacidad de los pacientes mientras permite a los investigadores realizar análisis. Por otro lado, los datos completamente sintéticos se crean desde cero basándose en reglas, modelos o simulaciones predefinidas y no representan datos del mundo real. Estos datos están diseñados para replicar la complejidad y variabilidad que se observa en escenarios del mundo real, lo que puede ser útil en situaciones donde la disponibilidad de datos es limitada.
Aplicaciones de los datos sintéticos en atención médica
Las aplicaciones de los datos sintéticos en salud son diversas y tienen el potencial de transformar la atención médica. Por ejemplo, tienen el potencial de estimar los beneficios de políticas de detección y atención médica, tratamientos o intervenciones clínicas, mejorar algoritmos de aprendizaje automático, como pipelines de clasificación de imágenes, preentrenar modelos de aprendizaje automático que luego se pueden ajustar para poblaciones de pacientes específicas y mejorar modelos de salud pública para predecir brotes de enfermedades infecciosas.
Por ejemplo, en el ámbito de la salud mental, se ha utilizado data sintética en combinación con procesamiento de lenguaje natural (PLN) para predecir diagnósticos y fenotipos de pacientes basados en informes de alta hospitalización. Los registros electrónicos de salud (EHRs, en inglés) contienen datos de PLN que se pueden utilizar para clasificar enfermedades complejas. Dado que la información de salud mental se considera especialmente sensible, el uso de texto sintético evita el riesgo de comprometer información confidencial y sensible.
Por otra parte, en el contexto de la pandemia COVID-19, los datos sintéticos también se utilizaron para mejorar la escasez de datos en estudios de imágenes médicas. Estos estudios han demostrado que el uso de datos sintéticos puede mejorar la precisión de la detección de COVID-19 en imágenes de tomografías computarizadas (TC) en comparación con los datos originales.
Asimismo, a los datos sintéticos se les relaciona con el concepto de “gemelos digitales” en la atención médica, los cuales representan réplicas virtuales de sistemas físicos o procesos que se utilizan para simular y predecir su comportamiento en tiempo real. En el ámbito de la salud, los gemelos digitales pueden utilizarse para crear modelos personalizados de pacientes, lo que permite optimizar los planes de tratamiento y mejorar los resultados. De igual manera, se han utilizado para optimizar la eficiencia y operaciones hospitalarias.
Desafíos y limitaciones
Como se mencionó anteriormente, los autores explican otro de los aspectos más importantes en relación con los datos sintéticos, como las preocupaciones de privacidad y seguridad. En este sentido, los autores detallan que la privacidad no debe ser considerada como una idea secundaria una vez que un sistema ya ha sido diseñado e implementado, sino que debe aplicarse un enfoque de “privacidad desde el diseño”, especialmente cuando se trabaja con datos clínicos. El desafío más importante clave es garantizar que los datos sintéticos derivados de información médica sensible no revelen involuntariamente detalles identificables sobre las personas ni conduzcan a una posible reidentificación de estos pacientes, ya que violaría principios de privacidad y protección de datos.
Si deseas conocer más sobre este tema puedes consultar el estudio completo: https://www.nature.com/articles/s41746-023-00927-3





