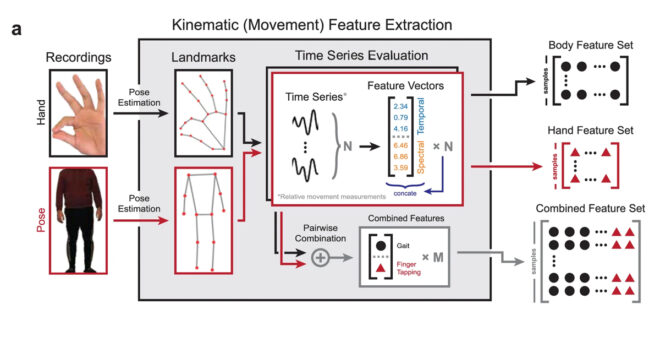
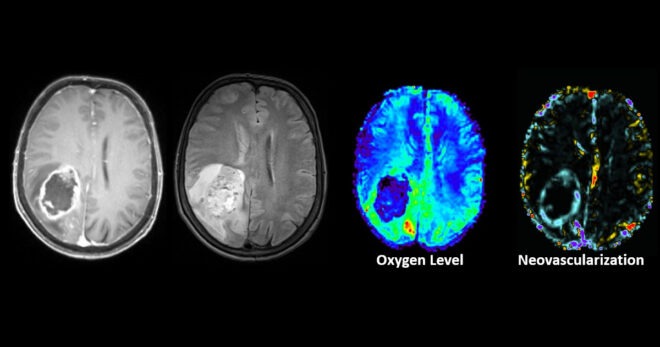
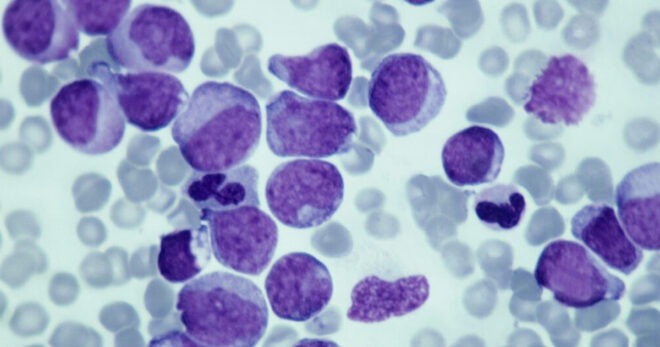
Big data
Machine learning ayuda a predecir síntomas de salud mental en adolescentes
Investigadores de Yale utilizaron un modelo de machine learning para interpretar cómo la interacción de factores neurobiológicos y ambientales influyen en la salud mental de