Investigadores muestran que fallan con frecuencia al detectar enfermedades cuando las imágenes presentan distorsiones comunes.
Un nuevo estudio publicado en npj Digital Medicine evaluó por primera vez, de forma sistemática, qué tan robustos son los modelos de visión-lenguaje (VLM, en inglés) al analizar imágenes médicas con artefactos. Estos modelos, que combinan procesamiento de imágenes con lenguaje natural, han demostrado avances importantes en tareas clínicas como responder preguntas sobre estudios radiológicos. Sin embargo, las imágenes utilizadas en la práctica médica real suelen presentar distorsiones causadas por movimiento, ruido, fallas del equipo o variaciones en la técnica, lo que plantea dudas sobre su confiabilidad.
Para investigar este problema, el equipo construyó un conjunto de pruebas que incluye imágenes de resonancia magnética (IRM), tomografías de coherencia óptica (OCT, en inglés) y radiografías de tórax. A partir de 600 imágenes originales, tanto normales como con patologías confirmadas, generaron versiones con cinco tipos de artefactos, en niveles “débiles” y “fuertes”. Los artefactos débiles representan deterioros que aún permiten interpretar la imagen, mientras que los fuertes corresponden a material prácticamente inutilizable en un entorno clínico. Con este material evaluaron a modelos ampliamente utilizados, como GPT-4o, Claude 3.5 Sonnet, Llama 3.2, BiomedCLIP y MedGemma.
En las imágenes sin distorsión, los VLM alcanzaron un desempeño moderado. Por ejemplo, en detección de tumores cerebrales por IRM, COVID-19 o neumonías en radiografías, y enfermedades maculares en OCT, los valores de exactitud se ubicaron entre 0.60 y 0.78 según el modelo y la modalidad. Los mejores resultados se observaron en sistemas entrenados de manera específica con datos médicos, como BiomedCLIP.
Esa situación cambió al introducir artefactos débiles. En promedio, los modelos redujeron su precisión entre 3 % y 10 %, con caídas más agudas en radiografías. Algunos artefactos, en especial el ruido aleatorio, provocaron descensos drásticos. En el caso de BiomedCLIP, su exactitud para detectar enfermedad pulmonar cayó casi 40% bajo esta interferencia. El estudio documenta ejemplos en los que los modelos confunden artefactos con lesiones reales (falsos positivos) o, por el contrario, pierden de vista alteraciones verdaderas (falsos negativos). De forma excepcional, ciertos artefactos, como recortes leves en MRI, incluso mejoraron el rendimiento de algunos modelos al obligarlos a enfocarse en la región de interés.
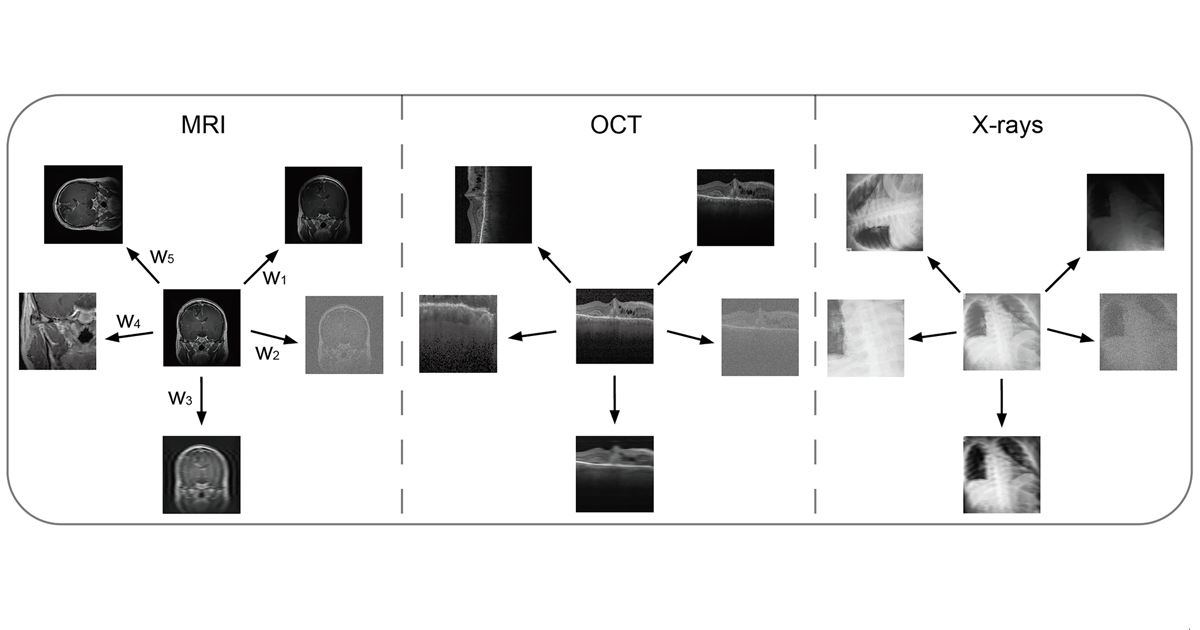
Cuando se analizaron las imágenes con artefactos fuertes, los resultados empeoraron considerablemente. Los modelos rara vez identificaron correctamente que la imagen era de mala calidad. En MRI, X-ray y OCT, la capacidad de detectar imágenes no utilizables osciló entre 0.11 y 0.23 para la mayoría de los sistemas, con la excepción de versiones específicas de Claude 3.5 Sonnet, que mostraron mejor desempeño. Según los autores, esta incapacidad para reconocer imágenes inadecuadas podría representar un riesgo en entornos clínicos, donde una evaluación errónea puede conducir a diagnósticos equivocados.
El estudio también analizó si las instrucciones dadas al modelo (“prompts”) influían en su desempeño. De manera general, los prompts menos restrictivos —como los que permiten razonamiento paso a paso— ayudaron a detectar imágenes de mala calidad, aunque no siempre mejoraron la detección de enfermedades. En algunos casos, estos mismos prompts hicieron que los modelos se negaran a dar un diagnóstico por consideraciones éticas, lo que también redujo su precisión medida de forma estricta.
Los autores complementaron sus pruebas con un conjunto de fotografías de fondo de ojo con artefactos reales, usados en el tamizaje de retinopatía diabética. Los resultados fueron consistentes: los modelos disminuyeron su precisión con artefactos y mostraron dificultades para identificar imágenes no evaluables. En esta modalidad, GPT-4o mostró la exactitud más alta en imágenes de buena calidad, mientras que MedGemma presentó la mayor sensibilidad para detectar imágenes fuertemente distorsionadas.
De acuerdo con los investigadores, estos hallazgos evidencian que los VLM aún no son suficientemente robustos para su uso en entornos médicos reales, donde las imágenes rara vez están libres de distorsiones. El trabajo subraya la necesidad de desarrollar evaluaciones estandarizadas de robustez, incluir pruebas con artefactos desde las etapas tempranas del diseño de modelos y crear sistemas capaces de identificar cuando una imagen no tiene la calidad suficiente para emitir un diagnóstico. Asimismo, recomiendan avanzar hacia modelos especializados y hacia técnicas de interpretación que permitan entender cómo los modelos procesan la información visual bajo condiciones imperfectas.
El estudio constituye una primera base para desarrollar evaluaciones más completas que consideren artefactos combinados, escalas más finas de distorsión y tareas multiclase más cercanas a la práctica clínica, con el objetivo de construir modelos más confiables y seguros para su uso asistencial.