Un nuevo estudio muestra que dividir tareas entre múltiples agentes de IA mantiene la precisión y reduce costos computacionales cuando se procesan grandes volúmenes de trabajo clínico.
Un equipo de investigadores del sistema de salud de Mount Sinai evaluó cómo distintos diseños de inteligencia artificial (IA) basados en modelos de lenguaje funcionan cuando deben manejar grandes volúmenes de tareas clínicas simultáneas. Sus resultados sugieren que organizar estos sistemas como equipos de múltiples agentes especializados puede mantener altos niveles de precisión y eficiencia, incluso cuando aumenta significativamente la carga de trabajo.
El estudio, publicado en npj Health Systems, analizó el desempeño de modelos de lenguaje de última generación bajo condiciones que simulan flujos de trabajo clínicos reales, en los que múltiples tareas llegan al mismo tiempo. En este contexto, los investigadores compararon dos enfoques, uno en el que un único agente de IA procesa todas las tareas y otro en el que un “orquestador” distribuye cada tarea a agentes especializados que trabajan de manera independiente.
“Lo que hemos descubierto es que los sistemas de IA se comportan de forma muy similar a las personas”, afirma el autor principal del estudio, el Dr. Eyal Klang. “Cuando se le pide a un sistema que haga demasiadas cosas diferentes a la vez, el rendimiento se ve afectado. Pero cuando un agente coordinador distribuye el trabajo entre agentes especializados, el sistema sigue siendo preciso, receptivo y mucho más eficiente, incluso bajo una gran demanda”.
En este sentido, los resultados mostraron diferencias claras entre ambos enfoques, en primer lugar, cuando el sistema utilizaba múltiples agentes coordinados, la precisión se mantuvo relativamente alta incluso al aumentar el número de tareas simultáneas. Por ejemplo, con lotes pequeños de cinco tareas, la precisión alcanzó 90.6%, y aunque disminuyó con cargas más altas, todavía se mantuvo en 65.3% cuando el sistema procesaba 80 tareas al mismo tiempo.
En segundo lugar, cuando un solo agente intentaba resolver todas las tareas en un mismo flujo, el rendimiento se deterioraba rápidamente. En ese escenario, la precisión cayó de 73.1% con cinco tareas a apenas 16.6% cuando se procesaban 80.
Según los autores, esta caída en el rendimiento puede explicarse por la sobrecarga del contexto de los modelos de lenguaje. Cuando un único agente recibe muchos problemas diferentes dentro de la misma conversación o cadena de instrucciones, su capacidad para concentrarse en la información relevante disminuye. En cambio, cuando cada agente especializado se encarga de una sola tarea, el modelo solo procesa los datos necesarios para esa decisión específica.
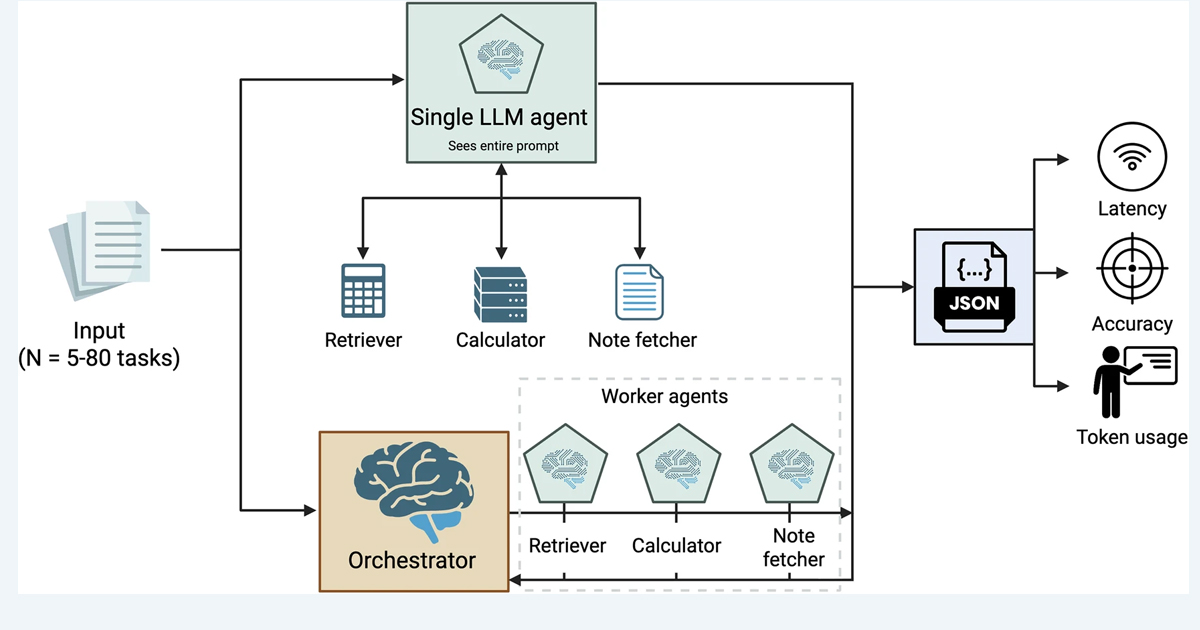
El sistema evaluado incluía tres tipos de tareas comunes en flujos de trabajo clínicos digitales. La primera consistía en recuperar artículos científicos relevantes desde bases de datos biomédicas como PubMed. La segunda implicaba extraer información estructurada de notas médicas de alta hospitalaria. La tercera se centraba en cálculos de dosificación de medicamentos basados en parámetros como peso corporal o superficie corporal.
Aunque estas tareas no representan toda la complejidad de la práctica clínica, los investigadores explican que constituyen “bloques básicos” que suelen integrarse en aplicaciones más amplias, como sistemas de apoyo a la decisión médica o herramientas de análisis de historiales clínicos.
Otro hallazgo importante fue el impacto en los recursos computacionales. El enfoque de múltiples agentes utilizó muchos menos tokens, la unidad básica de procesamiento de texto en los modelos de lenguaje. En algunos casos, la diferencia fue de hasta 65 veces menos tokens que el enfoque de un solo agente cuando se manejaban cargas altas de trabajo.
También se observaron diferencias en el tiempo de procesamiento. Aunque ambos sistemas tardaban más cuando aumentaba el número de tareas, el crecimiento de la latencia fue mucho más pronunciado en el modelo de agente único. En algunos casos, los modelos con esta arquitectura incluso fallaron antes de completar los cálculos, especialmente cuando se utilizaron modelos de menor tamaño.
El estudio evaluó cuatro modelos distintos con diferentes tamaños y capacidades. En general, los modelos más grandes mantuvieron mejor su estabilidad en el sistema de múltiples agentes, mientras que los más pequeños mostraron una degradación más rápida del rendimiento.
Los investigadores señalan que este trabajo es uno de los primeros en analizar cómo los modelos de lenguaje se comportan cuando se enfrentan a cargas de trabajo clínicas a gran escala, en lugar de evaluar un solo caso o paciente a la vez, como ocurre en muchos estudios previos.
Además de mejorar el rendimiento, la arquitectura basada en orquestador y agentes especializados podría ofrecer ventajas regulatorias. Al dividir las tareas en pasos claros y registrables, cada acción del sistema puede auditarse, lo que facilita rastrear cómo se generó una respuesta.
A pesar de estos resultados prometedores, los autores subrayan que el estudio se realizó con conjuntos de datos controlados y tareas con respuestas determinísticas. Por ello, consideran necesario evaluar esta arquitectura en flujos de trabajo clínicos reales y con supervisión de profesionales de la salud antes de su implementación práctica.
En el futuro, los investigadores planean estudiar si este enfoque también mejora el rendimiento en aplicaciones más complejas, como el razonamiento clínico, el resumen de historiales médicos o la interacción directa con pacientes. Si los resultados se confirman, los sistemas de IA médica podrían evolucionar hacia modelos colaborativos, en los que múltiples agentes especializados trabajen coordinadamente para apoyar la toma de decisiones en entornos clínicos de alta demanda.